
Agentic RAG Is Just Search That Finally Knows When to Stop
Agentic RAG Is Just Search That Finally Knows When to Stop
Static RAG was a vending machine.
You dropped a query in, it pushed out the top-k chunks, and your model tried to make sense of whatever fell into the tray. Half the time the right document was the eleventh result. The other half, the right answer needed three documents your embedder never connected.
Agentic RAG fires the vending machine and hires a researcher.
The Top-K Lie
Vector search assumes the question and the answer share enough surface vocabulary to land in the same neighborhood. They usually do not. A user asks about renewal pricing, the relevant clause lives under "term extension provisions," and cosine similarity shrugs.
Three failure modes the top-k pipeline never names:
- Vocabulary mismatch. The user's words and the document's words rarely align on the first pass.
- Multi-hop collapse. Questions that need two facts joined together get one fact, retrieved twice.
- Confidence theater. The pipeline returns something for every query, even when the right answer is "we do not have this."
Static RAG hides these failures behind a fluent paragraph. The model hallucinates the bridge between the chunks it received and the answer it owed.
The Researcher Pattern
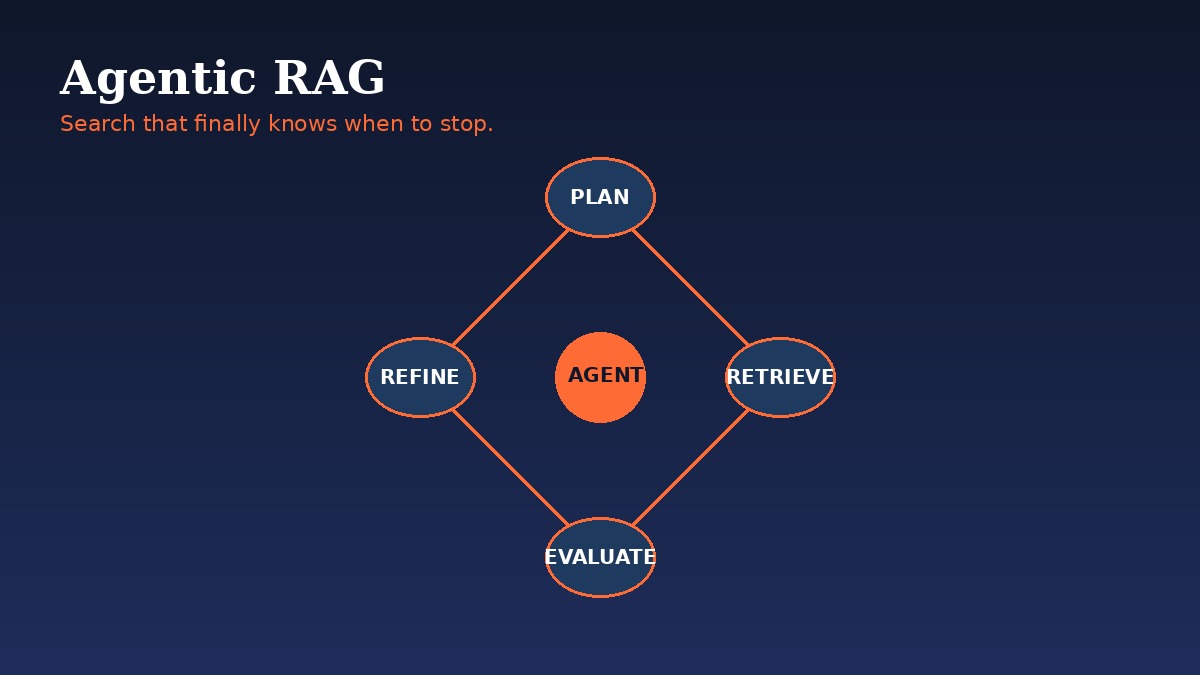
An agentic retrieval loop reframes the problem. Instead of one shot, the agent runs a small investigation. It reads the question, drafts a plan, picks a tool, fetches evidence, scores what came back, and decides whether to keep going. A January 2025 survey on arXiv catalogs the pattern under four agentic primitives: reflection, planning, tool use, and multi-agent collaboration.
The loop has shape. Five moving parts that matter:
- Query decomposition. Break the user's question into sub-questions the retriever can actually answer. Azure AI Search runs subqueries in parallel and merges them.
- Tool routing. Vector store, SQL engine, web search, internal API. The agent picks the right shelf, not just the nearest one.
- Evidence scoring. Each retrieved chunk gets evaluated for relevance and sufficiency before the agent commits.
- Self-correction. When results are thin, the agent rewrites the query and tries again rather than padding with garbage.
- Stopping criterion. The agent decides when it has enough, instead of always returning the same fixed number of chunks.
That last one is the unlock. Knowing when to stop searching is the whole job.
What the Agent Actually Decides
The interesting decisions happen between retrievals. Weaviate describes the agent as an iterative validator: retrieve, evaluate, re-retrieve, validate. Each loop is a tiny experiment with a hypothesis and a test.
The decisions look like this:
- Did the chunks I got back actually contain the entity the user named.
- Is one document sufficient, or do I need a second source to triangulate.
- Should I widen the query, narrow it, or pivot to a different tool entirely.
- Am I retrieving the same content over and over, which means I am stuck and should escalate.
- Has the user's intent shifted mid-conversation, and do I need to throw out my earlier context.
None of these decisions exist in vanilla RAG. The pipeline cannot reflect on what it does not measure.
The Latency Tax Is Real
Honest accounting matters. Multiple retrieval rounds cost time. Microsoft notes that adding an LLM to query planning adds latency, mitigated by smaller planner models and parallel subquery execution.
The math only works when you spend the latency on questions that earn it:
- Trivial lookups stay one-shot. If the agent can answer from a single chunk, it should not loop.
- Complex questions get the full investigation. Multi-hop, ambiguous, or compliance-sensitive queries justify the extra round trips.
- Planner and worker get split. Use a fast cheap model for routing, a stronger model for synthesis.
- Parallelism is mandatory. Subqueries fan out, results merge, latency stays bounded.
An agent that loops on every query is a worse vending machine. An agent that loops on the right queries is an analyst.
Where the Pattern Breaks
Production deployments hit the same walls in the same order:
- Loop runaway. Without a hard budget on retrieval steps, the agent spirals on hard questions and burns the call stack.
- Reflection blindness. Self-critique only catches errors the model can recognize. Subtle factual gaps slip through.
- Tool sprawl. Five retrievers become fifteen, the router gets confused, and accuracy drops below the static baseline.
- Eval poverty. Teams ship agentic RAG without an eval harness that distinguishes good loops from lucky ones.
Open implementations show the fix is structural: search budgets, parent-child chunking, parallel subgraphs with map-reduce aggregation, and a fallback when the budget is exhausted.
The Frameworks Are Catching Up
The infrastructure layer is consolidating fast. LangGraph, LlamaIndex, AutoGen, and Crew AI all converge on the same primitives: planner, retriever tools, reflection step, aggregation. Enterprise platforms wrap these into routing agents, query planning agents, and ReAct-style reasoning loops with shared memory.
The framework choice matters less than the discipline of the loop. A well-designed loop on a thin framework beats a sloppy loop on a thick one.
Stop Calling It Retrieval
The label "retrieval-augmented generation" undersells what is actually happening. Agentic RAG is not augmentation. It is investigation, conducted by a model that knows the difference between having an answer and having enough.
The vending machine never knew. The researcher does, and that is the upgrade.